Serverless vs. Always-On GPUs: How to Know Which Your Model Actually Needs
Most teams choose between serverless and always-on GPUs by gut feel. Here's how to make the decision with data — and why getting it wrong costs more than you think.
The Decision Most Teams Get Wrong
When you deploy an LLM inference endpoint, you face a choice: serverless GPUs that spin up on demand, or always-on GPUs that are ready to serve requests immediately. Most teams pick one and apply it everywhere. That's the mistake.
The right answer depends on your traffic pattern — and it's different for every model in your fleet.
What Serverless GPUs Actually Mean
Serverless GPU platforms (Modal, RunPod, and others) provision a GPU when a request arrives and release it when the request completes. You pay only for active compute time. Cold starts — the delay between request arrival and the first token — have historically been the main drawback, sometimes adding 20-30 seconds of latency.
Modal recently reduced cold starts by 40x using a combination of layer-persistent containers, FUSE-based filesystem mounting, checkpoint/restore, and CUDA-level checkpointing. That improvement makes serverless viable for use cases where it wasn't before.
But faster cold starts don't change the fundamental tradeoff. They just shift where the break-even point is.
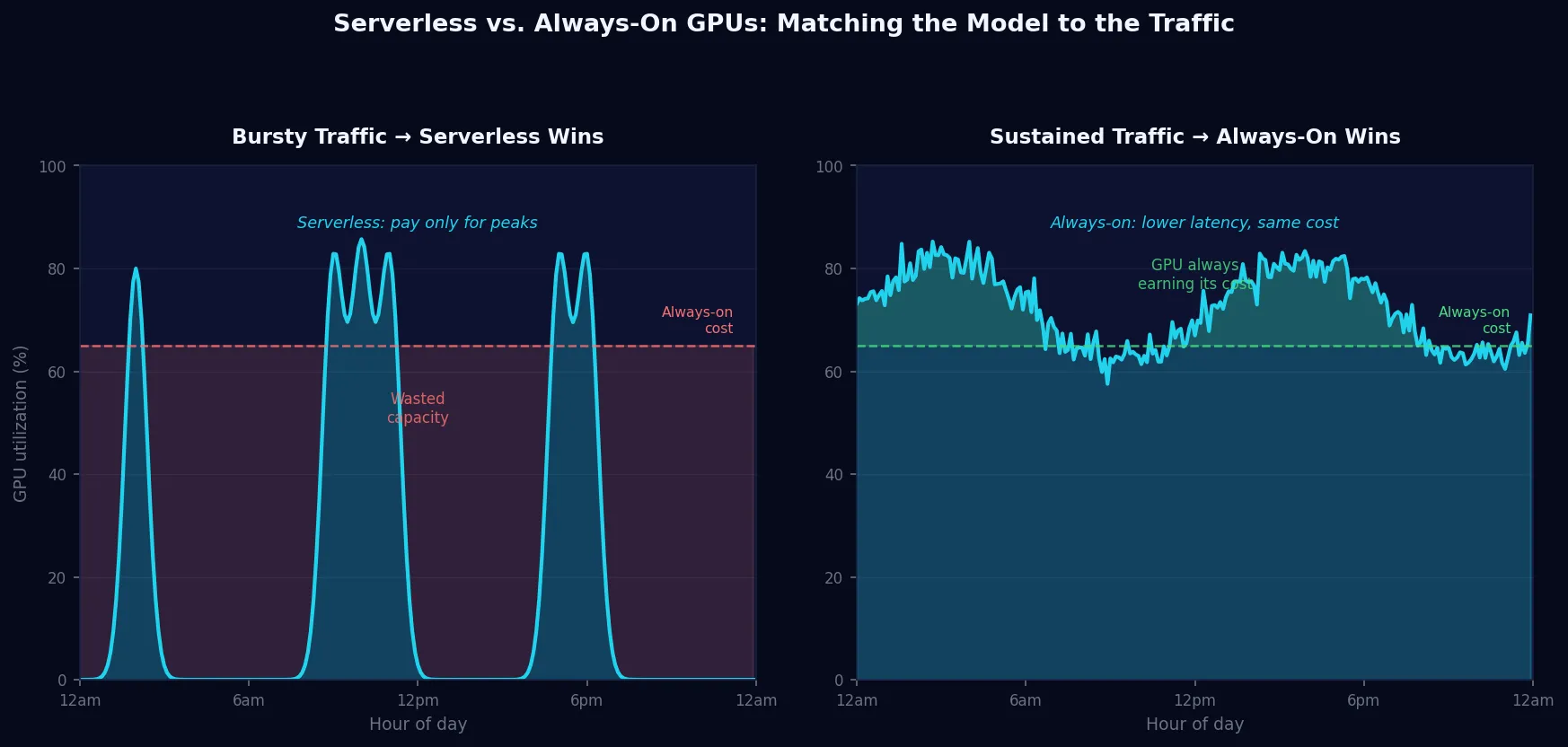
When Serverless Wins
Serverless is the right choice when your model has bursty or unpredictable traffic — requests that come in spikes, with significant quiet periods in between.
Examples:
- A batch processing endpoint that runs on-demand for a few hours per day
- A demo or internal tool used irregularly by a small team
- A fine-tuned model serving a niche use case with low but unpredictable volume
In these cases, an always-on GPU sits idle most of the time. You're paying for a GPU that isn't earning its cost. Even with the overhead of cold starts, serverless is cheaper — and with Modal's improvements, the latency penalty is now small enough that it doesn't affect user experience for most workloads.
When Always-On Wins
Always-on is the right choice when your model has sustained, predictable traffic — a steady stream of requests throughout the day with no meaningful idle periods.
Examples:
- A customer-facing chat endpoint handling hundreds of requests per hour
- A coding assistant integrated into a developer workflow with continuous usage
- A production RAG pipeline serving live application traffic
Here, serverless adds latency on every request for no benefit. The GPU would never go idle anyway, so you're paying the same compute cost either way — but with the added latency tax of cold starts on each new instance. Always-on is both cheaper and faster.
The Cost Model
The break-even calculation is straightforward in theory:
- Serverless cost = active compute time × per-second rate
- Always-on cost = reserved hours × hourly rate
There's an important pricing factor most teams overlook: serverless GPU rates carry a 20–40% premium over reserved rates on the same hardware. You're paying for the platform's convenience — the warm instance pool, the spin-up automation, the zero-idle promise. That premium shifts the break-even point lower than you'd expect. If serverless costs 30% more per GPU-hour, always-on becomes cheaper once your model hits roughly 50% utilization — not 70%.
Once you account for the serverless pricing premium, the break-even point shifts lower — often below 60% utilization depending on your provider. Below that threshold, serverless saves money despite the higher rate.
The problem is that most teams don't know their actual utilization per model. They have aggregate GPU metrics — overall cluster utilization — but not per-model traffic patterns. Without that granularity, the serverless vs. always-on decision defaults to instinct.
The Fleet-Level Problem
The decision gets harder when you're operating multiple models across multiple clusters.
A single inference cluster might have:
- Three models with sustained traffic that belong on always-on GPUs
- Two models with bursty traffic that belong on serverless
- One model that's been misclassified and is either wasting always-on capacity or paying unnecessary serverless cold start penalties
Without visibility into per-model traffic patterns, you can't make this decision systematically. You end up with a fleet where the placement is wrong for several models, and nobody knows which ones or what it's costing.
How to Make the Decision With Data
The signals you need are already in your infrastructure:
- Request rate per model over time — does it look like a flat line or a series of spikes?
- Active inference time vs. idle time — what percentage of each hour is the GPU actually serving requests?
- KV cache utilization — sustained high KV cache usage is a strong signal for always-on
vLLM, SGLang, and other inference servers expose these metrics through their Prometheus endpoints. The gap is a layer that aggregates them per model across your fleet and surfaces the placement recommendation with a cost delta attached.
That's the control plane decision. Not a serving-layer decision — a fleet management decision.
The Bottom Line
Serverless GPUs are getting better. Modal's cold start work is a genuine improvement that expands the range of workloads where serverless makes sense. But the improvement doesn't eliminate the need to match each model to the right serving strategy.
The teams that capture the full efficiency benefit are the ones who know — per model, per cluster — which deployment pattern actually fits. That requires visibility at the model level, not just the hardware level.
If you're running inference at scale and want to understand which models in your fleet are on the wrong serving strategy, piqc surfaces per-model utilization data without write permissions or agents. And if you want the fleet-level recommendations on top, reach out.