From the Paralleliq team.
Deep dives into architecture, performance tuning, and operational excellence.

The Next Layer of Inference Efficiency: Cross-Instance KV Cache and Multi-Stage Serving
Two developments in the vLLM ecosystem — LMCache's cross-instance KV cache sharing and vLLM-Omni's multi-stage serving — point at where inference efficiency problems are heading next, and why a one-time configuration decision won't keep up.

From GPU Waste Finding to Production Change: What Actually Happens in Between
Every GPU optimization tool will tell you what's wrong. Almost none of them tell you what happens next — between the moment an engineer agrees with a recommendation and the moment the fleet actually changes.

How Token Compression Changes Your GPU Sizing Math
Token compression reduces what you pay per API call. Most teams stop there. The infrastructure math changes too — shorter contexts mean smaller KV cache requirements, which means a different GPU tier, more concurrency, and a lower GPU bill. Here is how to recalculate.

What the Cloudflare–Replicate Acquisition Means for Your Inference Infrastructure
Cloudflare's acquisition of Replicate in November 2025 is the clearest signal yet that inference infrastructure is becoming a strategic layer in the internet stack. Here is what it means if you are a Replicate customer, a self-hosted inference team, or anyone trying to understand where the market is heading.

15 Foundation Models, 15 Different vLLM Configs
The open-weight model zoo now has 15+ production-grade options. Each one has a different architecture, memory profile, and vLLM configuration requirement. That's not a model selection problem — it's an ops problem.

Why MoE Models Break Your vLLM Configuration Rules
The configuration rules that work for dense models fall apart with Mixture of Experts. A DeepSeek-scale MoE model needs the memory of a 671B model but the compute of a 37B one — and most teams configure it wrong.
How to Configure vLLM for Production
vLLM configuration is normally done through trial and error. Wrong max_num_seqs, misconfigured KV cache, or a bad speculative decoding decision can silently destroy throughput and latency. Here's how to get it right before you touch a cluster.

The One Sequence That's Killing Your LLM Inference Performance
When LLM inference slows down, the instinct is to look at infrastructure. But sometimes the culprit is a single request — one sequence quietly sitting in your batch, degrading latency and burning GPU budget for everyone else.

Selling GPUs Is No Longer Enough — Why GPU Clouds Are Becoming Optimization Platforms
CoreWeave, Lambda, Crusoe, and RunPod all sell the same H100s at roughly the same price. The GPU clouds that survive the coming commoditization wave will be the ones that help enterprise customers run workloads well — not just the ones that have the most hardware.
The Two Business Models Running AI Inference — And Why They Have Completely Different GPU Problems
Fireworks, Together, and Groq sell tokens. Baseten and Modal sell deployments. The same GPU waste looks completely different from each seat — and fixing it requires a completely different pitch.

10 GPU Fleet Findings — And Who Each One Matters To
Not every GPU fleet problem looks the same from every seat. Here are the ten failure modes Paralleliq detects, what each one means, and why platform teams, GPUaaS providers, inference providers, and liquidity markets each care about different ones.

Your Online Inference Has an On-Call Engineer. Your Batch Jobs Run at 2am Alone.
Every AI team knows what their chatbot is doing right now. Nobody knows what their batch jobs cost. That's the gap — and it's where a surprising amount of GPU budget quietly disappears.

The GPU Shortage That Isn't
I asked a GPU cloud provider what their biggest pain point was. They said they're running out of GPUs. Here's why I think the real problem is somewhere else entirely.
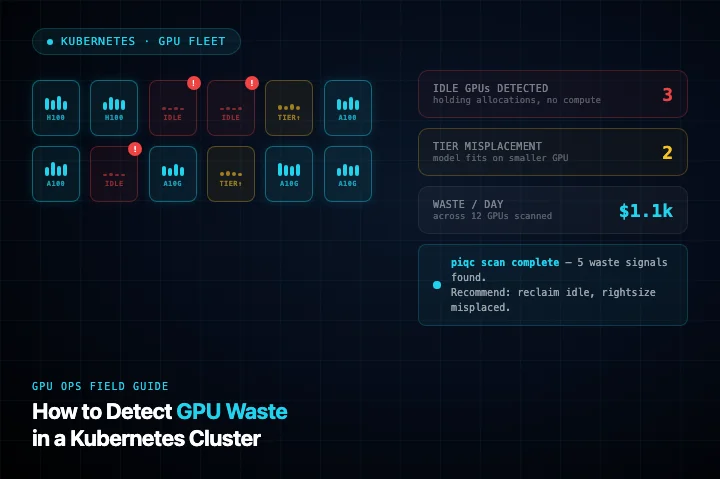
How to Detect GPU Waste in a Kubernetes Cluster
GPU waste in Kubernetes is largely invisible to standard monitoring. Here is what to look for, which metrics actually surface it, and how to go from suspicion to a concrete dollar figure.

InferOps: The Category Nobody Named Yet
MLOps ends when the model is deployed. FinOps starts when the bill arrives. The operational gap in between — keeping inference fleets healthy, efficient, and production-ready — is InferOps. And most teams are doing it manually.
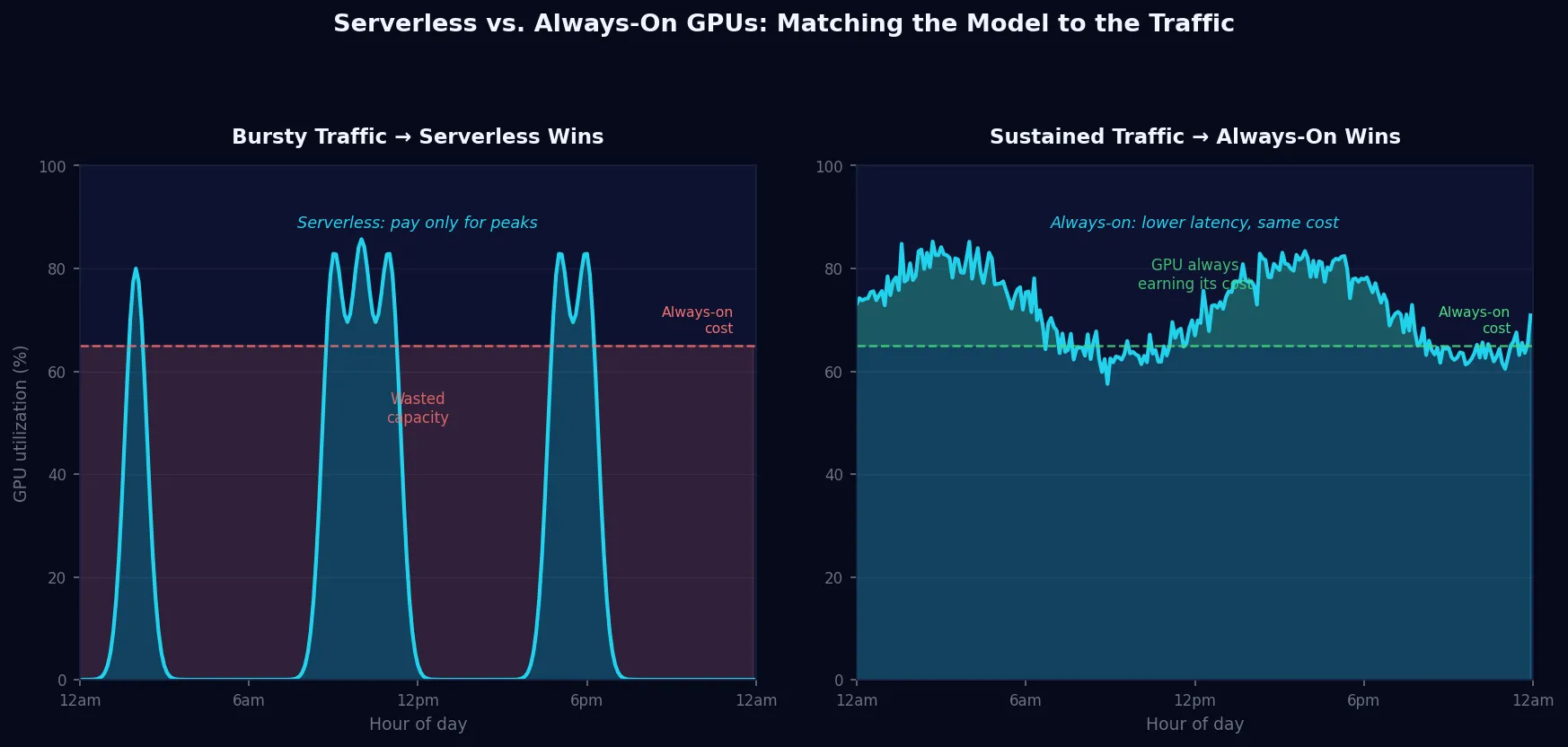
Serverless vs. Always-On GPUs: How to Know Which Your Model Actually Needs
Most teams choose between serverless and always-on GPUs by gut feel. Here's how to make the decision with data — and why getting it wrong costs more than you think.

MIG Partitioning Is a Step Forward. Here's the Layer It Still Doesn't Solve.
Multi-Instance GPU partitioning lets you stop renting full cards for workloads that only need a slice. But who decides which model goes on which slice — and how do you manage that decision across a fleet?

The LLM Inference Autoscaling Stack: What Each Layer Solves — and the Gap None of Them Close
KEDA, Thoras.ai, llm-d, NVIDIA Dynamo, KServe, Run:ai — each is real, each is useful. Here's what each layer of the inference autoscaling stack actually covers, and what the entire stack leaves unaddressed.

Paralleliq vs. Cast.ai: Two Different Answers to GPU Waste
Cast.ai's own 2026 report found average GPU utilization of 5% across 23,000 Kubernetes clusters. Both Paralleliq and Cast.ai are trying to fix this — but from different angles, at different layers, with different trade-offs.

Build vs. Buy: The GPU Optimization Layer Decision
Every team running GPU inference at scale eventually faces the same question: build an optimization layer internally, or buy one. The build path is deceptively expensive. Here's an honest breakdown.

Why GPU Fleet Management Needs a Tenant Model
Single-cluster GPU tools break the moment you have multiple customers, multiple clusters, or multiple regions. Here's the organizational model that makes fleet-level control actually work.

What is a Model-Aware Optimization Layer?
As GPU fleets scale across clusters and regions, traditional infrastructure tooling breaks down. A model-aware optimization layer is what comes next — and why the distinction matters.

How to Detect GPU Underutilization in a Kubernetes Inference Cluster
GPU utilization percentage is the most-watched metric in AI infrastructure — and the most misleading. Here's what to measure instead, and how to instrument your Kubernetes inference cluster to catch waste before it compounds.

vLLM OOM Errors: Root Cause Diagnosis Guide
Out of memory errors in LLM inference are rarely random. They follow predictable patterns — KV cache overflow, batch size misconfiguration, memory fragmentation. Here's how to diagnose which one you're dealing with.

GPU Right-Sizing: Matching Tier to Workload
Running a 7B model on an H100 is as wasteful as running a 70B model on an A10G. Right-sizing GPU tiers is one of the highest-leverage cost optimizations in inference — and most teams get it wrong.

KV Cache Pressure: Symptoms, Causes, and Fixes
KV cache pressure is the hidden performance killer in LLM inference. When the cache fills up, throughput collapses and latency spikes — often without a clear error message. Here's how to detect and fix it.

CPU vs GPU Bottlenecks in Agentic AI Workloads
Agentic AI doesn't just run inference — it reasons, calls tools, manages memory, and orchestrates multi-step workflows. That changes the bottleneck. Here's how to tell whether your constraint is CPU or GPU.

How to Reduce LLM Inference Costs Without Sacrificing SLA
GPU costs for LLM inference are significant and often poorly optimized. These are the highest-leverage levers — ranked by impact and implementation effort — for reducing spend without degrading latency or throughput.

GPU Fleet Observability: What to Monitor and Why
A single GPU dashboard is not fleet observability. At scale, the metrics that matter are aggregated, correlated, and surfaced as actionable signals — not raw telemetry. Here's what to build.

Serverless GPU Cold Start Latency: Causes and Solutions
Serverless GPU inference promises zero idle cost. The hidden trade-off is cold start latency — which for large LLMs can range from 30 seconds to several minutes. Here's what causes it and how to manage it.

Audit Trails for AI Infrastructure Changes
Who changed the GPU tier? Who approved the model rollout? Who scaled down the cluster before the incident? Without an audit trail, these questions take hours to answer. Here's how to build one.

Multi-Cluster GPU Visibility Across Providers
Most AI teams operate GPU infrastructure across multiple clusters, clouds, and providers. Getting a unified view of fleet health, cost, and utilization across all of them is one of the hardest operational problems at scale.

Beyond GPU Utilization: Why Compute Efficiency Is the New Metric That Matters
As agentic AI workloads blur the boundary between CPU and GPU work, measuring GPU utilization alone is no longer enough. Compute efficiency is the new metric that matters.

The Missing Layer in AI: Fleet Optimization as Competitive Advantage
The industry has over-invested in the data plane. The next frontier is not how fast you run models but how efficiently your fleet operates at scale — that's the optimization layer.

The Inference Stack: Routing and Serving Layers for LLMs in Production
A field guide to vLLM, TGI, Triton, TensorRT-LLM, SGLang, and Ollama — and the routing layers (L4, L7, inference-aware) that turn them into a production stack.

From Models to Agents: Why AI Infrastructure Is Becoming the Real Competitive Advantage
Agents aren't just longer prompts. They're multiplicative on infrastructure complexity — and the teams that build the right substrate win the next phase.

What Matters to a GPUaaS Tenant
Reliability, speed, and cost predictability — not fleet metrics. What tenants of GPU clouds actually look at every day.

Beyond Prompt → Code: The Real Systems Challenges Behind Coding Foundation Models
KV cache, latency-throughput tradeoffs, agent loops, repo-level reasoning. The systems work hiding behind 'just a model that writes code'.

What Matters to a GPUaaS Provider
An optimization layer view of fleet health, revenue, and risk — and the metrics that separate growing GPUaaS businesses from leaking ones.

The #1 Silent Killer of GPUaaS Businesses
It's not hardware. It's idle GPUs. The economics of dedicated-only models break at scale, and better utilization is what fixes it.

The GPU Platform Control Plane: Policy as Code, Not Just Schedulers
GPUs are sold as products but operated like infrastructure. A four-lane blueprint for what a real GPUaaS control plane looks like.

ModelSpec: A Blueprint for AI Model Intent
Model intent is scattered across docs, tickets, and someone's head. ModelSpec is a system of record for what your models are supposed to do.

The Financial Fault Line Beneath GPU Clouds
NeoClouds are caught between long-term GPU financing and short-term startup demand — the same structural mismatch that built the aircraft leasing industry.

Variability Is the Real Bottleneck in AI Infrastructure
Scarcity makes the headlines; variability is what actually breaks systems at scale. Why p99 latency, tail behavior, and explicit intent matter more than averages.

Orchestration, Serving, and Execution: The Three Layers of Model Deployment
Most teams don't struggle with AI because models are hard. They struggle because three different systems — execution, serving, orchestration — are asked to behave like one.

The Checklist Manifesto, Revisited for AI Infrastructure
Most AI deployments don't fail because the model is wrong. They fail because critical steps are missed. Checklists protect experts from complexity — and AI infra needs them too.

AI Applications Aren't Models — They're Distributed Systems
Every real AI deployment is no longer a service — it is a graph of interacting models, data systems, and control logic. AI applications have outgrown service-level abstractions.

The Missing Dependency Graph in AI Deployment
Every real AI application is no longer 'a model' — it is a graph of interconnected models and processing stages. Dependencies must become first-class citizens in model metadata.

Why ML Model Deployment Needs Its Own Best Practices
ML workloads behave nothing like microservices — different latency, throughput, resource, and cold-start dynamics. Model deployment needs its own operational discipline.

Cloud-Native Had Kubernetes. AI-Native Needs ModelSpec
For anyone who lived through the rise of cloud-native, the pattern unfolding in AI today feels familiar. The turning point in cloud-native was a specification — and AI is missing that layer.

The Invisible AI Deployment Footprint: Why MLOps Teams Lose Visibility as They Scale
If you ask most AI teams how many models they're serving in production, across every cloud and cluster, you'll usually get a long pause. The larger the organization, the more invisible the model footprint becomes.

Why LLM Inference Deployment is Still a Guessing Game
Training a model feels like progress; deploying it often feels like panic. Engineers pick GPUs, batch sizes, and runtimes blind — inference deployment shouldn't be guesswork.

Setting the Foundation — Why DevOps Must Evolve
Traditional DevOps was built for deterministic code. AI introduces software that learns and adapts, forcing DevOps to evolve from managing releases to managing intelligence.

AI in Philanthropy: From Donations to Data-Driven Impact
AI is shifting humanitarian work from reactive aid to predictive impact, but only as fast as the infrastructure beneath it — observability, orchestration, and compliance.

AI in FinTech: From Transactions to Trust
FinTech AI has moved from access to intelligence — fraud detection, underwriting, compliance, trading. The bottleneck now is infrastructure, not algorithms.

AI in Law: From Case Files to Code
AI is reshaping legal work — eDiscovery, contract analysis, research, compliance — by scaling judgment instead of replacing it. Infrastructure is becoming the next bottleneck.

The Hidden Backbone of AI: Building an Inference Service That Scales
Training gets the attention but inference is the invisible backbone that turns intelligence into business value. A scalable inference service is a system of systems.

The Hidden Costs of Manual Inference Services: Why Model Deployment Still Feels Like a Ticket Queue
Manual inference services are the hidden tax of modern AI operations — engineering overhead, waste, audit friction, drift, and team burnout that scale doesn't fix.

The New AI Stack: Why Foundation Models Are Partnering, Not Competing, with Cloud Providers
Foundation-model labs and hyperscalers aren't on a collision course — they're co-architecting a partnership-native AI stack where intelligence and infrastructure interlock.

When Law Meets Code: How AI Is Transforming the Legal Industry
For decades, the legal profession has centered on human reasoning as its scarcest commodity. Today, machine intelligence is entering law firms, courtrooms, and compliance departments — not to displace professional judgment, but to enhance it.

Finding the Exit: Where Cloud Compliance Ends and AI-Native Begins
Cloud compliance was about securing servers. AI-native compliance is about securing decisions.

AI in Healthcare: Precision Meets Trust
Healthcare AI sits at the intersection of precision, privacy, and public trust. The next decade will belong to systems that are not only accurate but also accountable — AI that is audit-ready, explainable, and compliant from day one.

The Next Frontier of Trust: Why AI-Native Compliance Starts Where Cloud Compliance Ends
The cloud era made trust a certification. The AI era makes trust a living system — observable, explainable, and provable.

Too Hot, Too Cold: Finding the Goldilocks Zone in AI Serving
Every AI inference system operates between two extremes: maintaining numerous active workers delivers excellent response times but inflates GPU costs, while keeping few or no workers eliminates expenses but introduces cold-start delays.

AI-Native vs. Cloud-Native: The Next Great Divide in Startup Infrastructure
Cloud-native gave startups speed. AI-native demands wisdom — observability, governance, and compliance built around learning systems, not just shipping code.

Bare-Metal GPU Stacks: The Hidden Alternative to Hyperscalers
AI workloads continue expanding rapidly, driving up infrastructure costs. Bare-metal GPU providers deliver comparable hardware at reduced prices — but the savings come with operational responsibility.

Hyperscaler Credits: Friend, Trap… or Both?
When infrastructure feels 'free,' efficiency takes a back seat. Hyperscaler credits can be both a growth accelerator and a hidden liability — depending on how strategically they're deployed.

GPU Idle Time Explained: From Lost Cycles to Lost Momentum
Idle GPUs don't just waste compute — they waste runway, talent, and momentum. The real cost of GPU stalls is paid in stalled experiments and burnt-out engineers.

Extending the Runway: Surviving the GPU Cost Crunch After Cloud Credits
When credits expire, costs spike dramatically. Five strategic levers help startups protect their timeline while maintaining iteration speed.

Inside the Infrastructure War: Hyperscalers vs. VPS in the AI Gold Rush
Hyperscalers offer a frictionless on-ramp; bare-metal providers offer raw GPU power for less. Most mature AI startups end up hybrid — the winning move is choosing smart, not picking sides.

Bare Metal vs. Hyperscaler: Why Startups Chase Raw GPU Capacity
AI today depends on a scarce resource: GPUs. Startups increasingly look past hyperscalers, seeking raw, unabstracted access to high-performance hardware through bare-metal providers.

The AI Factory: Turning Raw Data Into Business Outcomes
Think of AI as a factory: data is raw material, infrastructure and models are the machinery, business outcomes are the finished goods. The winners build the whole line.

Data Is the New Moat: Why Mid-Market Companies Have What Startups Need
AI-native startups move quickly with modern infrastructure, but they face a critical constraint: access to rich, domain-specific data. Meanwhile, mid-market incumbents possess exactly what startups need.

AI-Native Startups vs. Mid-Market Incumbents: Who Wins the Race?
Mid-market firms face a critical decision: adopt their competitor's AI SaaS to remain competitive, or build AI capabilities internally. The winners will be those who close the AI Execution Gap.

AI in Real Estate: From Startups to Enterprises, New Value Unlocked
Real estate represents one of the world's largest asset classes, yet many mid-market firms continue relying on manual processes. A fresh wave of startups is entering with AI-driven solutions for valuation, tenant experience, and property marketing.

The 3 Core Pillars of AI/ML Monitoring: Performance, Cost, and Accuracy
AI doesn't fail because of math — it fails because no one is watching. Three pillars determine whether AI investments generate ROI or quietly erode it.

From Filing Cabinets to AI Pipelines: The Evolution of Data Readiness
Unlike previous technologies, AI requires continuous, clean, and reliable pipelines to function effectively. Without this foundation, models fail to reach production or drift in use.

From Black Box to Glass Box: The Role of Observability in AI Systems
AI systems are frequently characterized as mysterious black boxes. Transforming AI into a glass box requires instrumenting infrastructure, cost, model health, and pipeline observability together.

The AI Execution Gap: Why Mid-Market Companies Struggle — and How to Close It
Mid-market companies recognize AI's potential but lack the resources to implement it effectively. The gap between understanding AI's promise and delivering tangible business outcomes defines the AI Execution Gap.

The Evolution of Data Centers: From Mainframes to AI-Driven Infrastructure
From 1950s mainframes to today's hyperscale GPU clusters, data centers have evolved alongside computing — and AI is now reshaping their architecture, networking, and economics.